

Data Wrangling Tools You Can Use: Terabytes and petabytes of data exist in the Internet age, and their growth is exponential. But how do we ingest this data and transform it into information that will enhance service availability? Valid, novel and comprehensible data is all that is required for knowledge discovery models in businesses. For this reason, businesses use analytics in various methods to unearth high-quality data. But where does everything begin? The solution is data manipulation. Let’s get underway!
What’s Data Wrangling?
The Data wrangling is the process of cleaning, structuring, and transforming unprocessed data into formats that facilitate data analytics procedures. Data wrangling is frequently required when working with messy and complex data sets that are not ready for data pipeline processes. Data manipulation transforms raw data into a refined state or refined data into an optimized, production-ready state. There are a number of well-known tasks in data manipulation.
- Combining multiple datasets into a single large dataset for analysis purposes.
- Examining missing/gaps in data.
- Eliminating anomalies or outliers from datasets.
- Standardizing inputs.
Large data repositories involved in data wrangling processes are typically beyond the scope of manual tailoring, necessitating the use of automated data preparation techniques to generate more accurate and high-quality data.
Data Wrangling Goals
Other objectives include preparing data for analysis, the primary objective.
- Creating valid and novel data from messy data to drive decision-making in businesses.
- Standardizing unstructured data into formats that Big Data systems can consume.
- By presenting data in an organized manner, data analysts can create data models faster, thereby saving time.
- Developing consistency, completeness, usability, and security for every dataset ingested or stored in a data warehouse.
Data Wrangling Common Approaches
Discovering
Before beginning data preparation tasks, engineers must comprehend how data is stored, its size, what records are maintained, the encoding formats, and other characteristics describing any dataset.
Structuring
This process involves organizing data into readily applicable formats. In order to make analysis easier, raw datasets may require structuring the columns, rows, and other data attributes.
Cleaning
Errors and other factors that can distort the data contained within structured datasets must be eliminated. Thus, cleaning involves removing multiple cell entries with identical data, deleting vacant and outlier data, standardizing inputs, and renaming perplexing attributes, among other tasks.
Enriching
Once data has passed the structuring and cleaning stages, it is necessary to evaluate data utility and supplement it with values from other deficient datasets to achieve the desired data quality.
Validating
The process of validating includes programming iterations that illuminate data quality, consistency, usability, and security. In addition, the validation phase verifies that all transformation tasks have been completed and marks the datasets as ready for the analytics and modeling phases.
Presenting
The wrangled datasets are presented/shared within an organization for analytics after all the datasets have been wrangled. Documentation of preparation steps and metadata generated during the data manipulation process is also shared in this stage.
Best Data Wrangling Tools
As we curated, the best Data Wrangling Tools are listed below.
1. Datameer
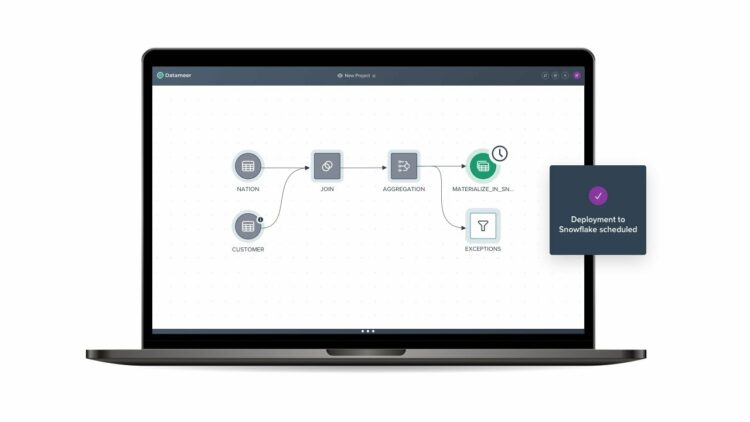

The tool maintains a comprehensive visual data profile that enables users to identify invalid, absent, or anomalous fields and values and the overall shape of the data. Datameer transforms data for meaningful analytics using efficient data layers and Excel-like functions while operating on a scalable data warehouse. In addition, Datameer offers a hybrid, code-and-no-code user interface to accommodate large data analytics teams that can readily construct complex ETL pipelines.
Features
Multiple User Environments
Low-code, code, and hybrid data transformation environments are provided to support both tech-savvy and non-technical users.
Shared Workspaces
Datameer enables teams to collaborate and use models to expedite projects.
Rich Data Documentation
Through metadata and wiki-style descriptions, notes, and remarks, Datameer supports both system- and user-generated data documentation.
2. Talend

Were you ever concerned about the diversity of your data sources? The unified approach of Talend enables rapid data integration from all of your data sources (databases, cloud storage, and API endpoints), enabling transformation and mapping of all data with seamless quality checks. Furthermore, data integration in Talend is made possible by self-service tools like connectors, which enable developers to import data from any source and properly categorize it automatically.
Features
Universal Data Integration
Businesses can wrangle any data type from various data sources using Talend, whether in the cloud or an on-premises environment.
Flexible
Talend moves beyond vendor or platform when creating data pipelines out of your integrated data. Talend enables you to run data pipelines created from ingested data anywhere.
Data Quality
Talend automatically purifies ingested data using machine learning capabilities like deduplication, validation, and standardization.
Support For Application & API Integrations
After your data has been given meaning using the Talend self-service tools, you can share it using user-friendly APIs. Talend API endpoints can expose your data assets to SaaS, JSON, AVRO, and B2B platforms through sophisticated data mapping and transformation tools.
3. OpenRefine
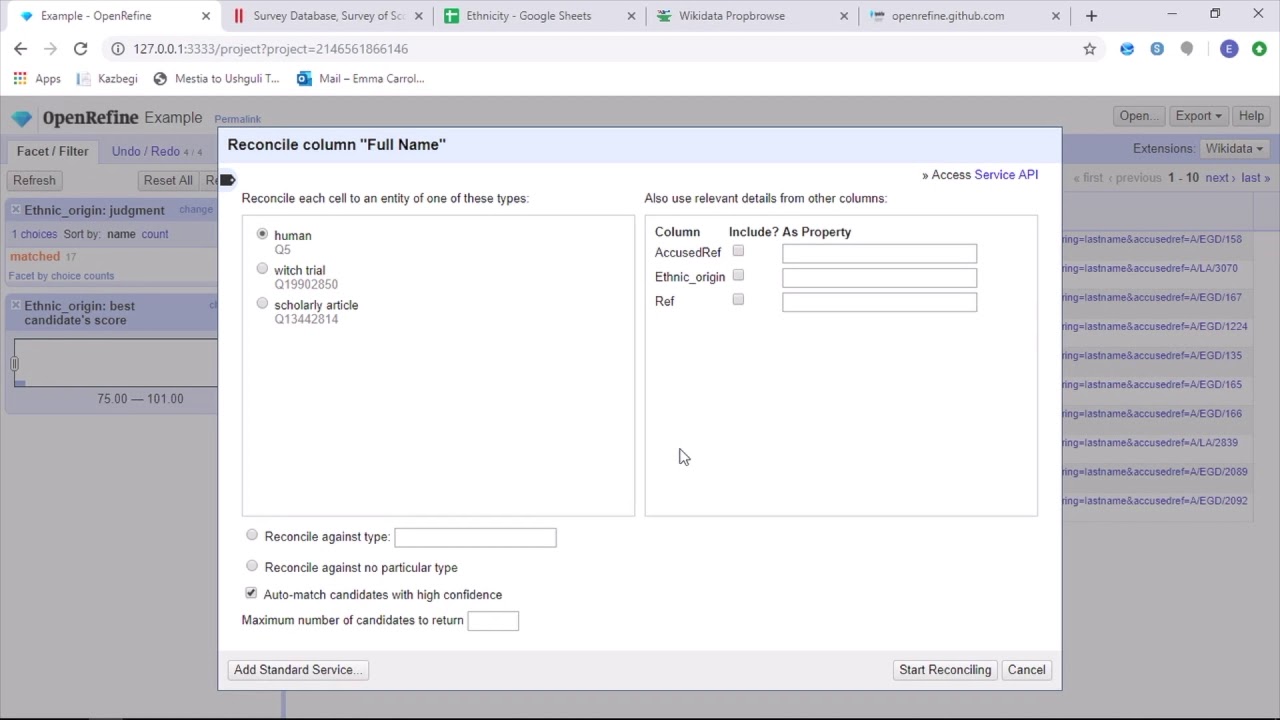
OpenRefine enables users to work on data as projects, where datasets from numerous computer files, web URLs, and databases can be incorporated, and projects can run locally on users’ computers. In addition, expressions allow developers to extend data cleansing and transformation to include tasks such as splitting/joining multi-valued cells, customizing faces, and retrieving data from external URLs into columns.
Features
Cross-platform Tool
OpenRefine is built to work with Windows, Mac, and Linux operating systems through downloadable installation packages.
Rich Set Of APIs
Contains the OpenRefine API, the data extension API, the reconciliation API, and other APIs facilitating user interaction and data interaction.
4. Trifacta

Using suggestions powered by machine learning, data is ranked and intelligently transformed with a single click and drag to accelerate data preparation. In addition, Trifacta allows non-technical and technical employees to manipulate data through visually compelling profiles. Thanks to its visualized and intelligent transformations, Trifacta is proud of its design with users in mind. As a result, users are protected from the complications of data preparation when ingesting data from data marts, data warehouses, or data lakes.
Features
Seamless Cloud Integrations
No matter where they reside, developers can import datasets for manipulation by supporting preparation work tasks across any cloud or hybrid environment.
Multiple Data Standardization Methods
Trifacta Wrangler has a number of mechanisms for recognizing data patterns and standardizing outputs. Data engineers can select standardization by pattern, function, or a combination of the two.
Simple Workflow
Trifacta organizes data preparation work as flows. A flow consists of one or more datasets and their corresponding algorithms (defined data transformation processes). Consequently, a flow reduces developers’ time importing, manipulating, profiling, and exporting data.
5. R

Features
Rich Set Of Packages
The Comprehensive R Archive Network (CRAN) provides data engineers access to over 10,000 standardized packages and extensions. This facilitates data manipulation and analysis.
Extremely Powerful
With available distributed computing utilities, R can perform simple and complex mathematical and statistical manipulations on data objects and datasets in seconds.
Cross-Platform Support
R is platform-independent and capable of running on various Operating Systems. Additionally, it is compatible with other programming languages that facilitate the management of computationally intensive tasks.
Also, Check:
Conclusion: Data Wrangling Tools
Data analytics is a complex process that requires data organization to draw meaningful inferences and make accurate predictions. Data Wrangling tools facilitate the formatting of vast quantities of unstructured data to facilitate advanced analytics. Choose the finest tool for your needs and become an expert in analytics!